1. We propose PSG-Bench: a challenging evaluation dataset featuring 5K complex text prompts (2K synthetic + 3K real-world) for advanced T2I models.
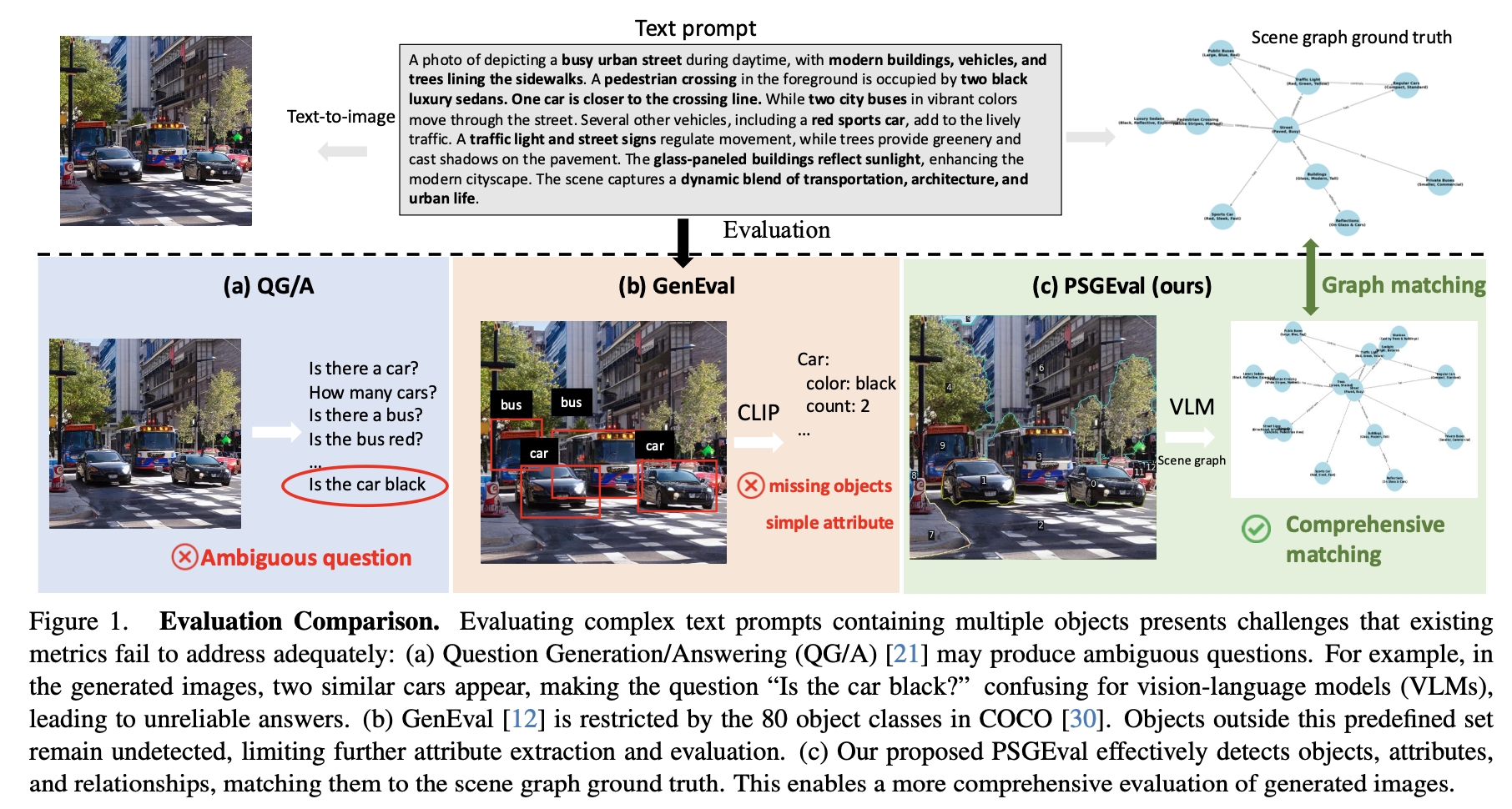
2. We propose PSGEval: a novel scene graph-based \textbf{evaluation metric} that comprehensively assesses both foreground and background content generation. We improve the detection base metric using scene graph to provide accurate assessment without using any QG/A methods avoiding the ambiguity in question generation and vision language model bias when answering these questions.
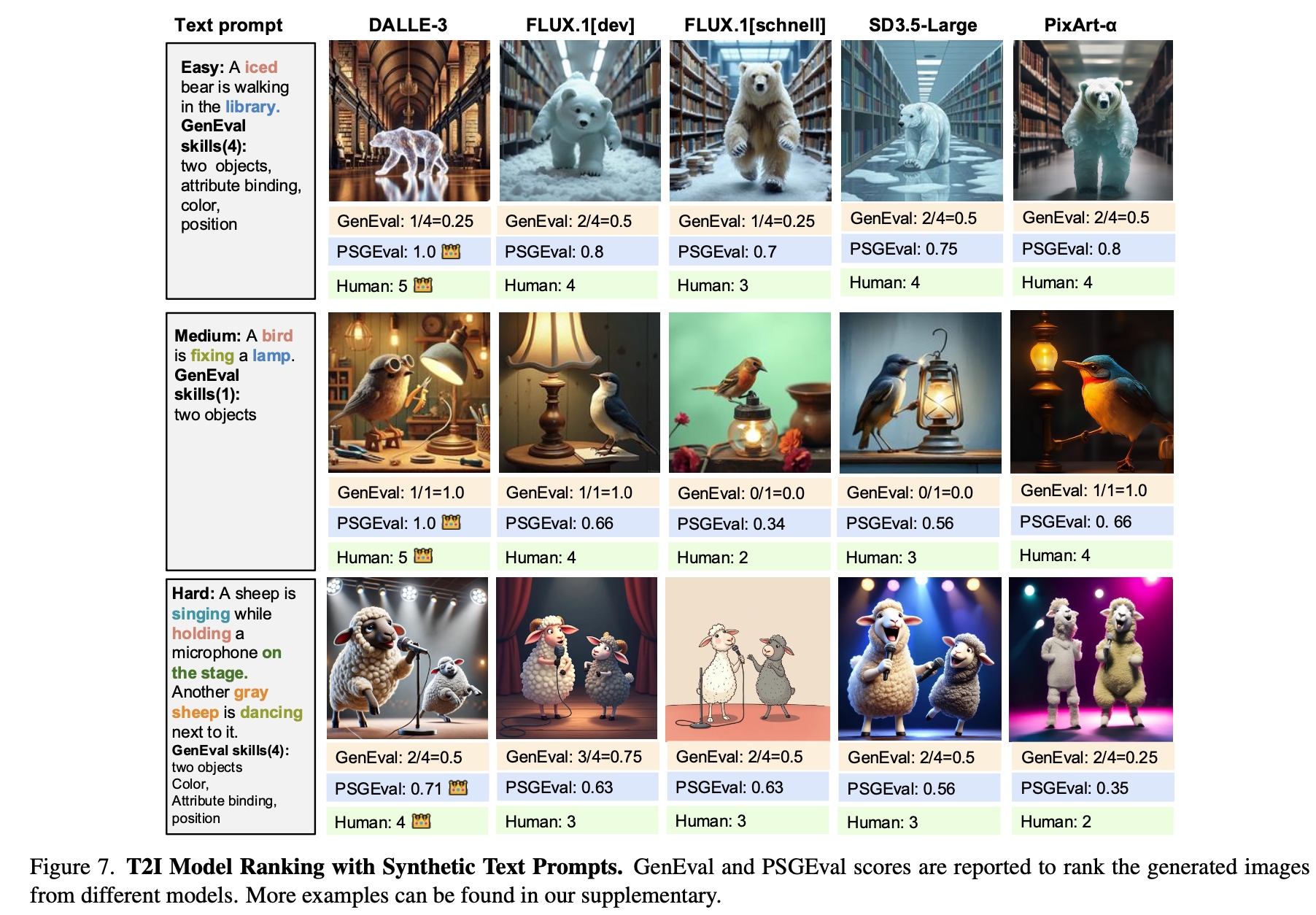
3. Comprehensive analysis: We rank recent state-of-the-art T2I models based on PSGEval and conduct human alignment studies to validate the effectiveness of our metric.
Text-to-image (T2I) models have advanced rapidly with diffusion-based breakthroughs, yet their evaluation remains challenging. Human assessments are costly, and existing automated metrics lack accurate compositional understanding. To address these limitations, we introduce PSG-Bench, a novel benchmark featuring 5K text prompts designed to evaluate the capabilities of advanced T2I models. Additionally, we propose PSGEval, a scene graph-based evaluation metric that converts generated images into structured representations and applies graph matching techniques for accurate and scalable assessment. PSGEval is a detection based evaluation metric without relying on QA generations. Our experimental results demonstrate that PSGEval aligns well with human evaluations, mitigating biases present in existing automated metrics. We further provide a detailed ranking and analysis of recent T2I models, offering a robust framework for future research in T2I evaluation.

@article{deng2025psg,
author = {Xueqing Deng and Linejie Yang and Qihang Yu and Chenglin Yang and Liang-Chieh Chen},
title = {Leveraging Panoptic Scene Graph for Evaluating Fine-Grained Text-to-Image Generation},
journal = {arxiv},
year = {2025}