
1. We propose a caption annotation pipeline leveraging panoptic segmentation to create a high-quality, detailed caption dataset comprising 143K annotated images. The resulting annotations are comprehensive, accurate, and include grounding masks, making this dataset substantially larger than recent detailed caption datasets.
2. We validate the utility of our proposed dataset across various fine-grained Image-to-Text (I2T) and Text-to-Image (T2I) tasks, including detailed caption generation, Panoptic segmentation and Grounded Captioning, visual question answering (VQA), referring segmentation, and text-conditioned image generation. Experimental results show that our dataset significantly enhances model performance across all these tasks.
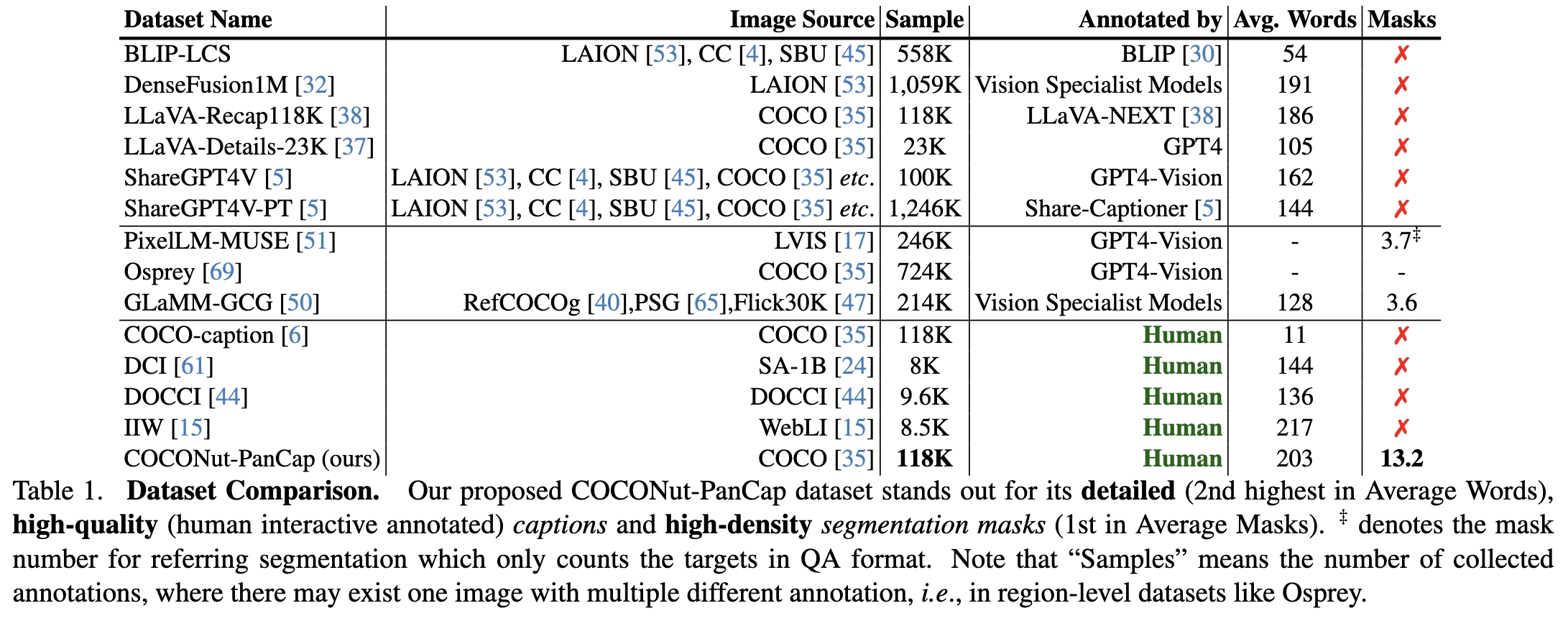
This paper introduces the COCONut-PanCap dataset, created to enhance panoptic segmentation and grounded image captioning. Building upon the COCO dataset with advanced COCONut panoptic masks, this dataset aims to overcome limitations in existing image-text datasets that often lack detailed, scene-comprehensive descriptions. The COCONut-PanCap dataset incorporates fine-grained, region-level captions grounded in panoptic segmentation masks, ensuring consistency and improving the detail of generated captions. Through human-edited, densely annotated descriptions, COCONut-PanCap supports improved training of vision-language models (VLMs) for image understanding and generative models for text-to-image tasks. Experimental results demonstrate that COCONut-PanCap significantly boosts performance across understanding and generation tasks, offering complementary benefits to large-scale datasets. This dataset sets a new benchmark for evaluating models on joint panoptic segmentation and grounded captioning tasks, addressing the need for high-quality, detailed image-text annotations in multi-modal learning.


@article{deng2024coconut_pancap,
author = {Xueqing Deng and Qihang Yu and Ali Athar and Chenglin Yang and Linejie Yang and Xiaojie Jin and Xiaohui Shen and Liang-Chieh Chen},
title = {COCONut-PanCap: Joint Panoptic Segmentation and Grounded Captions for Fine-Grained Understanding and Generation},
journal = {arxiv},
year = {2025}